This is the multi-page printable view of this section. Click here to print.
Components
- 1: Agents
- 2: Assignments
- 3: Data Sources
- 4: Offset
- 5: ETCD
- 6: API Server
- 7: Web UI
- 8: Workers, Jargon and Distributed Locks
1 - Agents
An agent is simply a running instance of Idra. Idra is designed to run in cluster mode, which enhances its ability to scale effectively. In this mode, all agents within the system connect to a shared ETCD instance. ETCD serves as a distributed key-value store that helps manage configuration data and state across multiple instances of the application.
By having all agents share the same ETCD instance, Idra ensures that they can communicate and coordinate their activities seamlessly. This shared architecture allows the system to scale horizontally, meaning that you can add more agents to handle increased loads without sacrificing performance.
Moreover, using a centralized ETCD instance is crucial for implementing locks that prevent concurrent processing on the same data sources. When multiple agents attempt to access the same resource simultaneously, it can lead to data inconsistencies and processing errors. The locking mechanism provided by ETCD ensures that only one agent can process a given data source at any time. This prevents conflicts and guarantees that the integrity of the data is maintained throughout the processing cycle. Overall, this architecture not only enhances scalability but also improves the reliability and efficiency of data handling within the system.
2 - Assignments
Assignment
An assignment is an association between a sync and an agent that is processsing that sync.

How syncs are processed
In a cluster of agents with more than one member, synchronization work is balanced among all elements within the cluster. Each synchronization task is handled by a single agent at a time. If an agent is added to the cluster or if an agent crashes, a rebalancing process is triggered, redistributing all assigned synchronization tasks.
When an agent crashes, the synchronization tasks assigned to the failed agent are reassigned to other agents within the cluster. This mechanism is somewhat similar to Kafka’s rebalancing process, which relies on Zookeeper. Also it is similar to shard management in some databases.

3 - Data Sources
Data Sources
A data source is a placehgolder for data about a connection to some data. It is used in UI for mantain a copy of the most used data source connections.
Data Sources Management
Data sources could be managed via UI.

4 - Offset
In Idra, an offset serves as a crucial mechanism for tracking the last identifier processed during synchronization. This offset plays a vital role in ensuring that the system accurately monitors which data has been successfully processed, thus preventing duplicate or missed entries. In many synchronization strategies, this offset is stored in ETCD, a distributed key-value store that helps maintain information about the most recently processed identifier. Typically, this identifier can be represented as either an integer or a timestamp, depending on the specific use case and the nature of the data being handled.
Given the importance of the offset in managing data integrity and synchronization, it is essential to ensure that ETCD is as durable as possible. Durability refers to the ability of the system to preserve data even in the face of failures, such as server crashes or network issues. Running ETCD in cluster mode is considered the best option for achieving this level of durability. In cluster mode, multiple ETCD nodes work together to replicate data, providing redundancy and increasing the likelihood that the stored offsets remain safe and accessible.
Moreover, the user interface of Idra does allow for the manual adjustment of the offset. However, this feature should be approached with extreme caution. Changing the offset manually can lead to significant issues, such as data inconsistencies or unintended reprocessing of messages. Therefore, it is crucial to fully understand the implications of any changes made to the offset before proceeding. Ensuring that you have a clear plan and thorough understanding of the data flow is vital for maintaining the integrity and reliability of the synchronization process.
In summary, the use of offsets in Idra is essential for effective synchronization and data management. Proper handling of these offsets, especially in conjunction with a robust ETCD configuration, is key to ensuring the system’s reliability and performance.
More info about clustering in ETCD here:
5 - ETCD
ETCD plays an important role in the application. ETCD is a highly reliable distributed key-value database designed to be used as a coordination data store for distributed applications.
Here are some of its key features:
Distributed architecture:
ETCD is designed to operate in a distributed environment and to be able to scale horizontally. It can run on a cluster of machines working together to provide a reliable service.
Distributed consensus:
ETCD uses a distributed consensus algorithm to ensure that all machines within the cluster have a consistent copy of the data. This distributed consensus algorithm is called Raft.
RESTful API:
ETCD provides a RESTful API that allows applications to access the data stored in it easily and conveniently. ETCD’s RESTful API is designed to be simple and intuitive to use.
Data consistency:
ETCD ensures that data is always consistent and correct. This means that all changes made to the data are quickly and reliably propagated to all machines within the cluster.
Security:
ETCD provides a range of security mechanisms to protect the data. This includes authentication and authorization, encryption, and key management.
Open source:
ETCD is an open-source project that is available for free use and modification. This means that developers can contribute to the code and improve it to meet their specific needs.
ETCD is used in this application to ensure that one and only one agent performs data synchronization. It allows for the election of a leader who is responsible for rebalancing the work of the agents when a new agent is added and is no longer available (due to deletion or crash), and when something is changed at the sync level such as the addition or removal of a sync.
The agent is written in Golang to simplify the process of managing the code that handles concurrency. In fact, it makes heavy use of Goroutines, which simplify the writing and management of concurrency.
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
6 - API Server
The Web server allows access to all synchronization information present in ETCD via API. The API server is written in Golang using the Gin framework, and this server is used by the Web client UI. GIN is a lightweight and fast web framework written in Go that enables the creation of scalable and high-performance web applications. Here are some of its key features:
Routing:
GIN offers a flexible and easy-to-use routing system, allowing for efficient handling of HTTP requests. You can define routes, manage route parameters, use middleware to filter requests, and more.
Middleware:
GIN supports the use of middleware to modularly handle HTTP requests. There are many middleware available, including logging middleware, error handling middleware, security middleware, and more.
Binding:
GIN offers a binding system that automatically binds HTTP request data to your application’s data types. You can easily handle form data, JSON data, XML data, and more.
Rendering:
GIN provides a flexible and easy-to-use rendering system, allowing for easy generation of HTML, JSON, XML, and other formats.
Testing:
GIN provides a great testing experience, with features such as integration test support and the ability to easily and intuitively test HTTP calls.
Performance:
GIN is known for its high performance and ability to easily handle high-intensity workloads. You can use GIN to create high-performance web applications, even in high concurrency environments.
In summary, GIN is an extremely useful web framework for creating web applications in Go. Thanks to its flexibility, high performance, and wide range of features.
7 - Web UI
Login
Default credentials to login in the Web UI, are admin/admin. Idra Web UI is a custom component not Open Source.
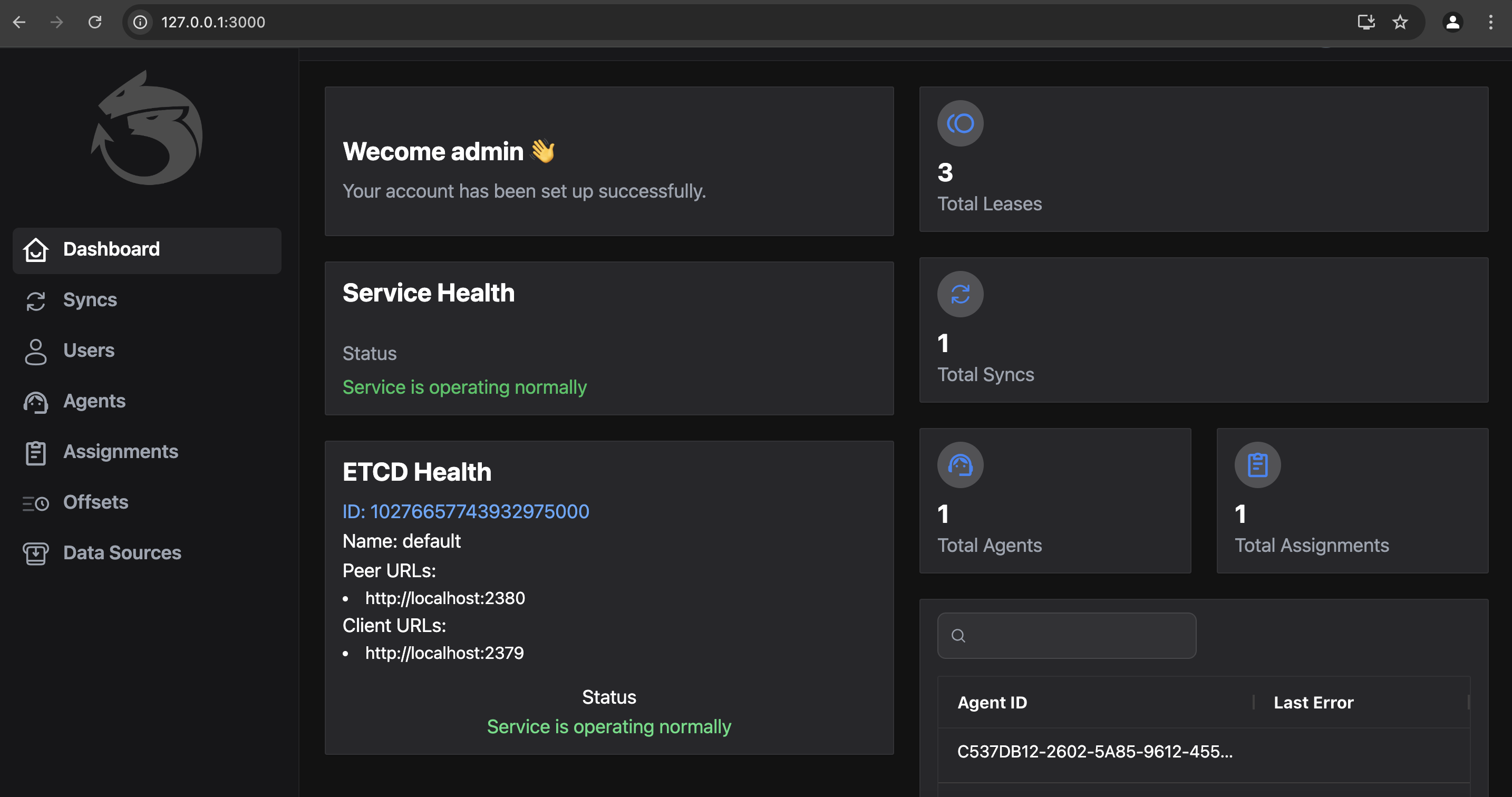
Dashboard
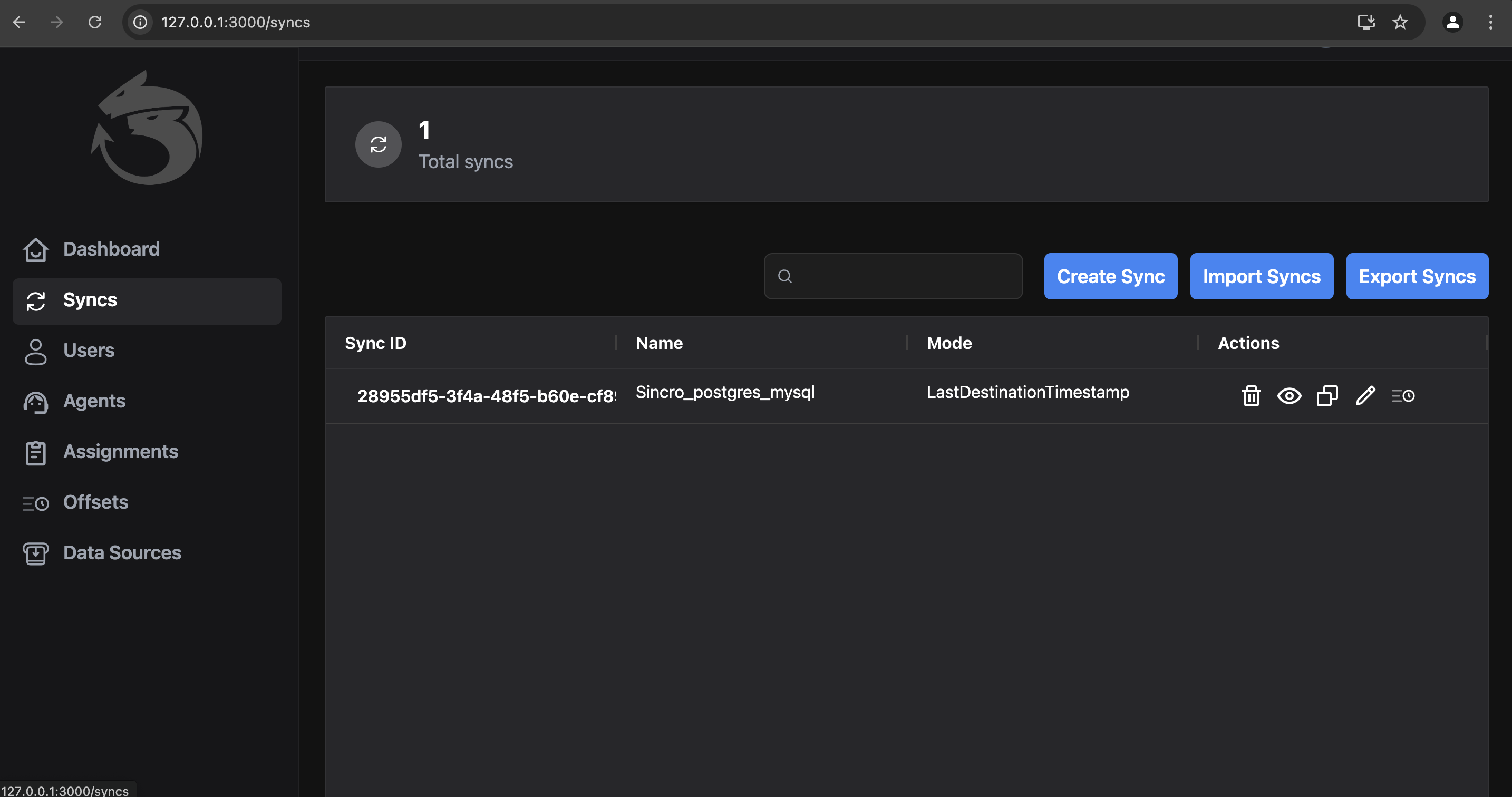
Sync: List of Syncs
Sync: Edit a sync
Users: Users Management View
Users: Create a new user for login
8 - Workers, Jargon and Distributed Locks
Worker Each worker node is responsible for processing one or more syncs. A sync is an object that contains a source connector, from which data is retrieved, and a destination connector, where the data is written. In its simplest configuration, a worker can use a JSON file and be launched without the support of ETCD in single mode. Idra can also be launched in cluster mode (multiple instances are run to increase computing capacity). The supported connectors at the moment are:
Postgresql
Mysql-Mariadb
Sqlite
Microsoft SQL Server
MongoDB
Apache Kafka
Amazon S3
Custom API
Here are some concepts present in Idra:
Sync: Data synchronization process consisting of a source and a destination
Connector: Source or destination provider that connects to a database, sensor, middleware, etc.
Agent: Instance of Idra responsible for executing syncs and connectors
ETCD: Distributed database based on the key-value paradigm.
Each worker, besides being responsible for processing synchronizations, also implements specific algorithms for distributed concurrency. By using leader election, the system implements the ability to distribute the load and redistribute computation if a worker fails or a new worker is started. The leader election algorithm, or distributed consensus algorithm, is a mechanism used by distributed systems to select a node within the system to act as a leader.
Distributed Lock
Each synchronization process is guaranteed to process a single synchronization process and uses a distributed lock to achieve this result. A distributed lock is a mechanism used in distributed systems to coordinate concurrent access to shared resources by multiple nodes. Essentially, a distributed lock functions as a global semaphore that ensures only one entity at a time can access a particular resource.
The idea behind the distributed lock is to use a distributed coordination system, in this case, we use ETCD, to allow nodes to compete for control of the shared resource. This coordination system can be implemented using a variety of techniques, including election algorithms, communication protocols, and other mechanisms.
When a node requests control of a resource, it sends a request to acquire the distributed lock to the distributed coordination system. If the lock is available, the node acquires the lock and can access the shared resource. If the lock is not available, the node waits until it becomes available.
It is important to note that a distributed lock can be implemented in different modes. For example, a distributed lock can be exclusive, meaning that only one node at a time can acquire it, or it can be shared, meaning that multiple nodes can acquire it simultaneously. The choice of the type of distributed lock depends on the specific requirements of the distributed system in which it is used.